Articles & case studies

Infor CloudSuite Data Migration for the City of New Orleans
Project Summary
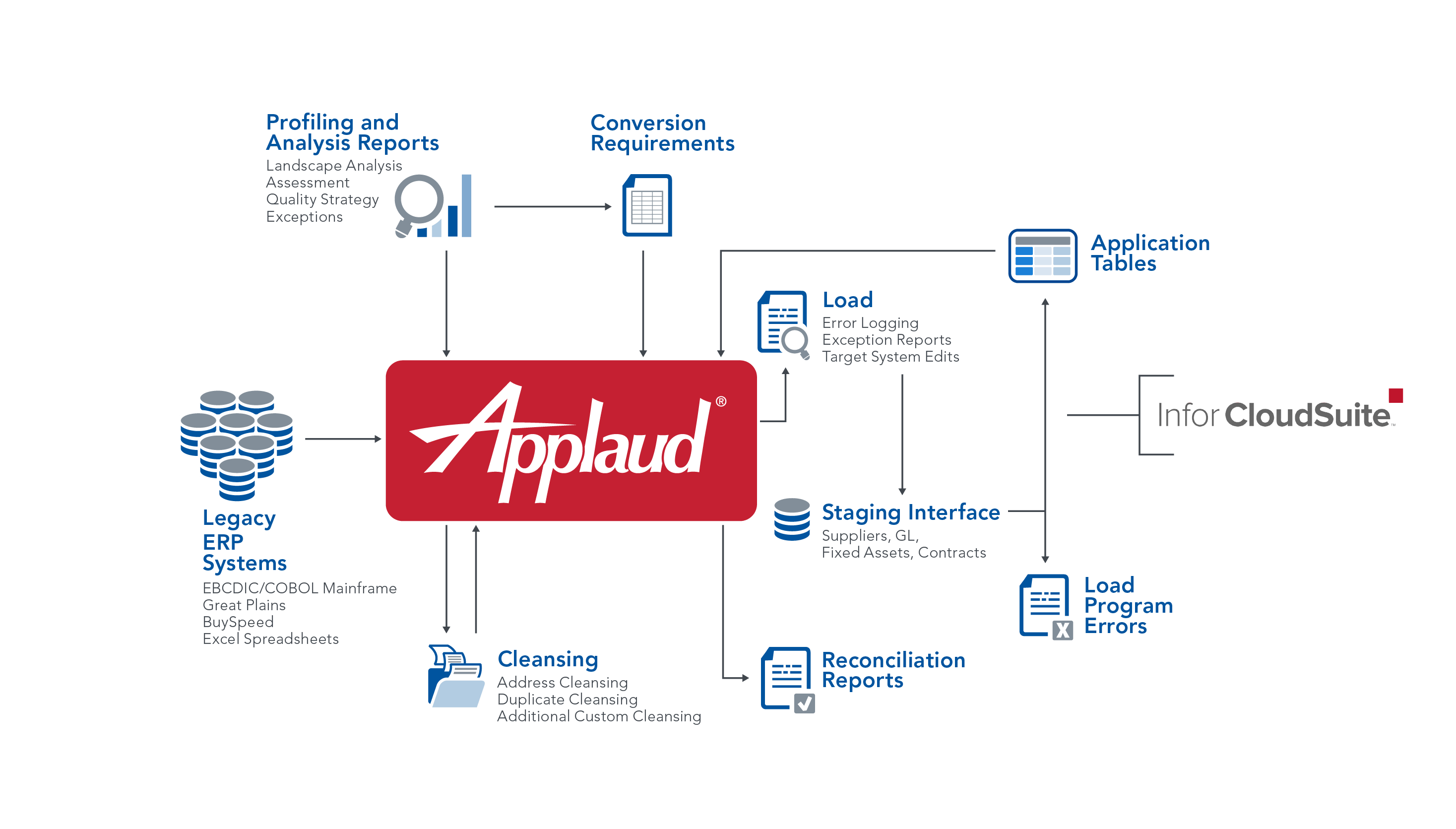
The City of New Orleans embarked on a complex business transformation project, Project BRASS, which included the implementation of Infor CloudSuite Financials and Supply Management applications. To implement the Infor CloudSuite solution, the existing business data from several disparate legacy applications (including an IBM mainframe (VSAM), Great Plains, BuySpeed, and other various spreadsheets) needed to be extracted, cleansed, transformed, migrated, and reconciled. Additionally, Federal government audit and reporting rules required 20 years of financial data history to be migrated to prove grants were administered correctly through the aftermath of Hurricane Katrina and other major events that impacted the city over the years. Recognizing the inherent risk and challenge that data posed to the success of the implementation, the city selected Definian to perform the data migration.

Project Risks
The data migration risk on this implementation was amplified by the implementation’s high profile, underlying data complexities, and limited internal resources. Additional factors included:
- Lack of understanding of the legacy applications’ underlying data, which was magnified the farther back in history that the data came from
- Significant data quality issues within the mainframe because of limited functionality set up decades ago
- Duplicate information within and across disparate data sources
- Complex vendor classification rules and migration requirements
- New GL accounting structures required extensive restructuring and reconciliation processes
- Substantial and lengthy historical data requirements, including 14 million general ledger records across 20 years of financial history
- Additional target system (MHC Software) needed to be implemented to accommodate the City’s complex contract attachment requirements
- Constant turnover without adequate knowledge transfer across City resources
“Definian is one of the best, if not the best, contractors that I have ever worked with.” – City Project Manager
Mitigating the Risks
To mitigate the identified risk factors, Definian leveraged several techniques to ensure that the data was ready for each test cycle and production cutover. Additionally, Premier ensured that the City employees, Infor consultants, and MHC consultants were educated, informed, and prepared for each aspect of the data migration.

- Performed a data assessment that provided clarity to the underlying data across the entire data landscape.
- Applaud’s mainframe data capabilities automatically accessed the EBCDIC data, significantly accelerating the process by eliminating the need for custom COBOL extracts from the City IT resources.
- Applaud’s powerful deduplication processing identified and consolidated duplicate vendor data across the landscape.
- Definian’s Infor CloudSuite CTQ (Critical-to-Quality) validations assisted with previewing conversion results and identifying records that will fail Infor’s system requirements and client’s functional business requirements, enabling the entire project team to address many issues before the actual loads were processed.
- Powerful delta and exception-based reporting focused the City’s limited resources on changed, new, and problematic data throughout the entire implementation cycle.
- Readiness dashboards that tracked essential metrics from the creation of mapping specifications to final load statistics were regularly shared with the PMO and kept management informed of the overall status.
- Definian’s data readiness process drove the project team to ensure that the data was ready for each test cycle and go-live by monitoring data quality issues, transformation issues, missing cross-references, and missing configurations.
“We are a public sector client and we would hire Definian for future conversions in a heartbeat. In fact, whether my next big conversion project is public or private sector, I will be reaching out to Definian for an opportunity to work on the project.” – City Project Manager
The Results
The combination of Definian’s data migration experts, Applaud data migration software, and our
EPACTL methodology ensured that the data migration was successful. the value Definian brought to the implementation was summed up in the following comment from the City made in front of the entire implementation team, “Definian is one of the best, if not the best, contractors that I have ever worked with.”
Definian’s approach made it possible to identify and resolve legacy and target data issues ahead of time, avoiding issues at go-live. Definian’s tools automated the vendor survivorship and merging process, facilitated the complex financial history requirements, processed the raw mainframe data, and generated detailed audit trail reporting. ’s expert consultants worked with the City and the various implementation partners to unravel the business requirements and drive data issues to completion before each test cycle and go-live.
The Applaud® Advantage

To help overcome the expected data migration challenges the organization engaged Definian’s Applaud® data migration services to eliminate the risk from their data migration and ensure the overall success of their transformation.
Three key components of Definian’s Applaud solution helped the client navigate their data migration:
- Definian’s data migration consultants: Definian’s services group averages more than six years of experience working with Applaud, exclusively on data migration projects.
- Definian’s methodology: Definian’s EPACTL approach to data migration projects is different than traditional ETL approaches and helps ensure the project stays on track. This methodology decreases overall implementation time and reduces the risk of the migration.
- Definian’s data migration software, Applaud®: Applaud has been optimized to address the challenges that occur on data migration projects, allowing the team to accomplish all data needs using one integrated product.


How to Halt Endless Requirement Changes
An IT project is a complex system of software, data, people, and requirements. Software goes through versions, data points move, and people evolve, but requirements stand out as the most fluid element of a project. If we study how requirement changes impact software, data, and people, we can better understand how to avoid the problems of endless requirement changes.
Kitchen Sink Syndrome, Loss Aversion, and Scope Creep
Anyone who has remodeled a kitchen knows that it is difficult to have restraint when the project gets started. What starts as a simple sink replacement ends with heated floors and a smart refrigerator. The same problem appears on IT projects. The allure of new features and a sleek interface could tempt project members into scope changes, even where there is not a strong business case for the feature.
Another psychology concept at play on IT transformation projects is loss aversion. In some cases, customizations serve a real business value or could even be a competitive differentiator for the enterprise. For example, you could be a furniture manufacturer that will configure finished products with any one of ten thousand fabrics – something far beyond the standard number of options. This level of variant configuration may go beyond the limits of many out-of-the-box ERP's but because it is a competitive differentiator for the company, it might merit implementation in the new system despite the complexity.
In other cases, however, a legacy customization goes against best practices and should rightly be dropped when migrating to a new system. The fear of losing a feature could tempt functional leads to demand its inclusion in scope. Together kitchen sink syndrome and loss aversion contribute to scope creep. Features, and sometimes entire modules, are added for emotional reasons instead of demonstrated business value.
The Risk of Cascading Failures
Enterprise scale software is a perfect example of a complex system. One property of complex systems, is that small disturbances can have outsize impact on the entire system. Consequently, seemingly minor changes to requirements or configuration create risk for the entire project.
For example, consider the common task of emailing specification changes between team members, like a new code value to be used in a Contract conversion. If this code value happens to contain a hyphen, then Outlook might automatically update this to be an em dash in the outgoing email. This updated value is copied to the documentation, cross-references, and the conversion program while the original value is configured in the system. When the conversion program runs this simple mix up would lead to massive failures in the Contract conversion, which impacts other areas like Customer-Item Cross-Reference selection, and lead to Sales Order lines having incorrect pricing. A single character can make the difference between a healthy test cycle and a disastrous one.
Even simple changes can be high risk because of the impact they have on the wider system. As the go-live date approaches, the risk associated with code changes grows. For project managers, it is critical that the team understands there is a cutoff date – well in advance of the final go-live – at which point all changes must stop.
Asking the Right Questions
Avoiding endless requirement changes require discipline and a strong adherence to project management principles. A solid project plan will define the scope of your project, establish milestones, and will be referenced throughout the life of the project. Unforeseeable complexities might arise, but a strong foundation will mitigate many challenges.
As your project progresses, requirements change and additional wants are added to the wish-list. Ask yourself a list of questions:
- How does a newly proposed task fit into the scope of the overall project?
- Will it affect the budget? The schedule?
- Do we have resources to assign to this task?
- How will this change affect other aspects of the project?
Even the smallest change to a data mapping element can, as seen in the Contract example, affect all sides of the project. Force a conversation with others – not just your own team – about the change or task you want to add. Additionally, talk about why you are not doing something. These conversations can save hours fixing missteps that could have been avoided.
Communication – The Key to Good Juggling
It can seem overwhelming to juggle all the moving parts of an IT project while addressing continual changes from multiple tracks. Documentation and communication are imperative in keeping the project on track, within scope, and under budget. On day one, when laying out the project goals, your team should also lay out a method of tracking changes. Changes should only be implemented after proper documentation and written approval. You will then be able to trace the source of new failures, hold team members accountable, and understand how the project has evolved from the initial plan.
Specification changes should be documented in a way that all team members and management can access the information. The corresponding technical changes should also be documented through comments within the relevant code. Code comments can highlight how a small tweak affects pieces of code further down the line, and in turn, the converted data. This makes risk more visible within the technical team and helps highlight a potential point of failure ahead of time.
Good documentation allows team members to share how they have contributed to the project. However, it will not prevent a project from deviating from the original scope. Scope maintenance requires ongoing communication between all project members. This includes contract discussions and cost overruns. Approach these conversations earlier rather than later.
Ultimately, avoiding endless requirement changes means establishing and promoting the mission of the project. A project meant to standardize business processes will look different than one seeking to improve customer relations. A project meant to minimize IT spend is different from one that optimizes the supply chain. Understanding and communicating the project goals increases buy-in from the entire team, helps establish scope, and is the foundation for your team’s success.

Data Literacy – Underpinning Data Monetization
Leveraging one’s data literacy skills allows them to identify the various use cases to grow revenue, reduce costs, or manage risks for successful Data Monetization. Healthcare is an industry were Data Literacy and Management has been constantly growing and maturing due to the state and federal mandates to support a Health Insurance Payor’s member.
Health Insurance Payors understand that members have a great deal of options to choose from when selecting their carrier year over year; many companies anchor their business motto on the member experience. This translates to Health Insurance Payors striving to excel at marketing, claims management, member appeal process efficiency, and ensuring that members are reaping the benefits provided to them through state and federally mandated regulations. Some examples where one may find that the organization’s mantra of improving the member’s experience may be impacted follow.
- Improper claim denials due to invalid or incorrect provider NPI, or perhaps the providers are not credentialed accurately, and out-of-network charges are applied for in-network providers may increase member appeals
- A member’s physical address changes to a nearby state, which is still within the insurance payor’s jurisdiction. The member may suffer from a medical condition that has specific mandates for care depending upon the state where the member resides. If the address metadata is not accurately captured or updated timely, the member may be denied claims for medication, supplies, or services that would otherwise be covered in adherence with the state mandates.
Working together, Definian can review your organization’s priorities, identify monetization opportunities, and corroborate use cases that resonate with business, leadership, and technology teams. We will work with you to leverage and expand your data literacy by considering possibilities such as complying with state and federal regulations related to provider credentialing, promoting growth initiatives through member data quality improvements, or reducing administrative costs by retiring or sunsetting applications and reports that have reached the end of their useful life.
Our team will help your organization trace the value of your data from use cases through business drivers to quantify the value of your program, affording you the opportunity to showcase your Data Monetization Investments. Reach out to us today!
Who's Responsible for What on Complex Data Migrations
There are four main teams involved on data migration projects; the data migration team, the data owners, the application\functional team, and overall program management. Frequently, responsibilities for across the multiple teams fall to the same person. These groups work together throughout the entire implementation to ensure that the data is ready for go-live, migrated within the cutover window, and validated within the target application. Without the proper input and feedback from each of these groups, the risk of failure greatly increases. The aim of this post and the RACI chart below is to outline the roles and responsibilities of each of these groups as it pertains to data migration.
If you have questions about data migration, data management, or just love data, let's connect. My email is steve_novak@definianintl.com
Main skills\knowledge needed for the data migration
- Data Owners: Understanding of the legacy system data design, data structures, and business requirements
- Functional Team: Understanding of the target system data design and new business requirements
- Data Migration Team: Intimate understanding of data profiling, cleansing, transformation, and migration techniques. In addition, they need to be skilled at documenting data migration processes at a functional and technical level, be detail oriented, highly organized, and understand data structures and business requirements. On projects where there is are no one is knowledgeable about the legacy systems data design, the data migration team also needs to be able to fill that gap and have the tools and techniques needed to quickly gain the understanding of how the legacy systems work.
- Program Management: Understanding of the entire implementation and how to implement\manage the overall project plan.
Extract Raw Data From Legacy Applications
- Responsible - Data Migration Team
- Accountable - Data Owners
- Consulted - Functional Team
- Informed - Program Management
Create Profile\Legacy Landscape Reports
- Responsible - Data Migration Team
- Accountable - Data Owners
- Consulted - Functional Team
- Informed - Program Management
Review Profile\Legacy Landscape Reports
- Responsible - Data Owners & Functional Team
- Accountable - Data Migration Team
- Consulted - Functional Team
- Informed - Program Management
Define Analysis Reporting Requirements for Legacy Data Cleansing
- Responsible - Data Owners
- Accountable - Data Migration Team
- Consulted - Functional Team
- Informed - Program Management
Define Analysis Reporting Requirements for Data Mapping
- Responsible - Functional Team
- Accountable - Data Migration Team
- Consulted - Data Owners
- Informed - Program Management
Define Analysis Reporting Requirements for Data Enrichment
- Responsible - Functional Team
- Accountable - Data Migration Team
- Consulted - Data Owners
- Informed - Program Management
Define Data Mapping\Data Design Requirements
- Responsible - Data Owners
- Accountable - Functional Team
- Consulted - Data Migration Team
- Informed - Program Management
Create and Manage Data Quality Strategy
- Responsible - Data Migration Team
- Accountable - Data Owners
- Consulted - Functional Team
- Informed - Program Management
Create and Manage Data Enrichment Strategy
- Responsible - Data Migration Team
- Accountable - Data Owners
- Consulted - Functional Team
- Informed - Program Management
Cleanse Data within the Legacy System
- Responsible - Data Owners
- Accountable - Data Migration Team
- Consulted - Functional Team
- Informed - Program Management
Develop Data Migration Programs
- Responsible - Data Migration Team
- Accountable - Data Owners
- Consulted - Functional Team
- Informed - Program Management
Develop Cutover Plan
- Responsible - Program Management
- Accountable - Data Migration Team
- Consulted - Data Owners
- Informed - Functional Team
Unit Test Data Conversion Programs
- Responsible - Data Migration Team
- Accountable - Data Owners
- Consulted - Functional Team
- Informed - Program Management
Validate Data in Target Application
- Responsible - Data Owners
- Accountable - Functional Team
- Consulted - Data Migration Team
- Informed - Program Management
Develop Reconciliation\Data Audit Requirements
- Responsible - Data Owners
- Accountable - Functional Team
- Consulted - Data Migration Team
- Informed - Program Management
Develop\Execute Programs that Automate Reconciliation\Data Audit Requirements
- Responsible - Data Migration Team
- Accountable - Data Owners
- Consulted - Functional Team
- Informed - Program Management
Validate Converted Data
- Responsible - Data Owners
- Accountable - Functional Team
- Consulted - Data Migration Team
- Informed - Program Management

Consolidating 11 ERPs into Oracle Cloud
Project Summary
After being bought by a private equity firm, a $4.4B data center equipment and service provider embarked on a complex system modernization initiative.
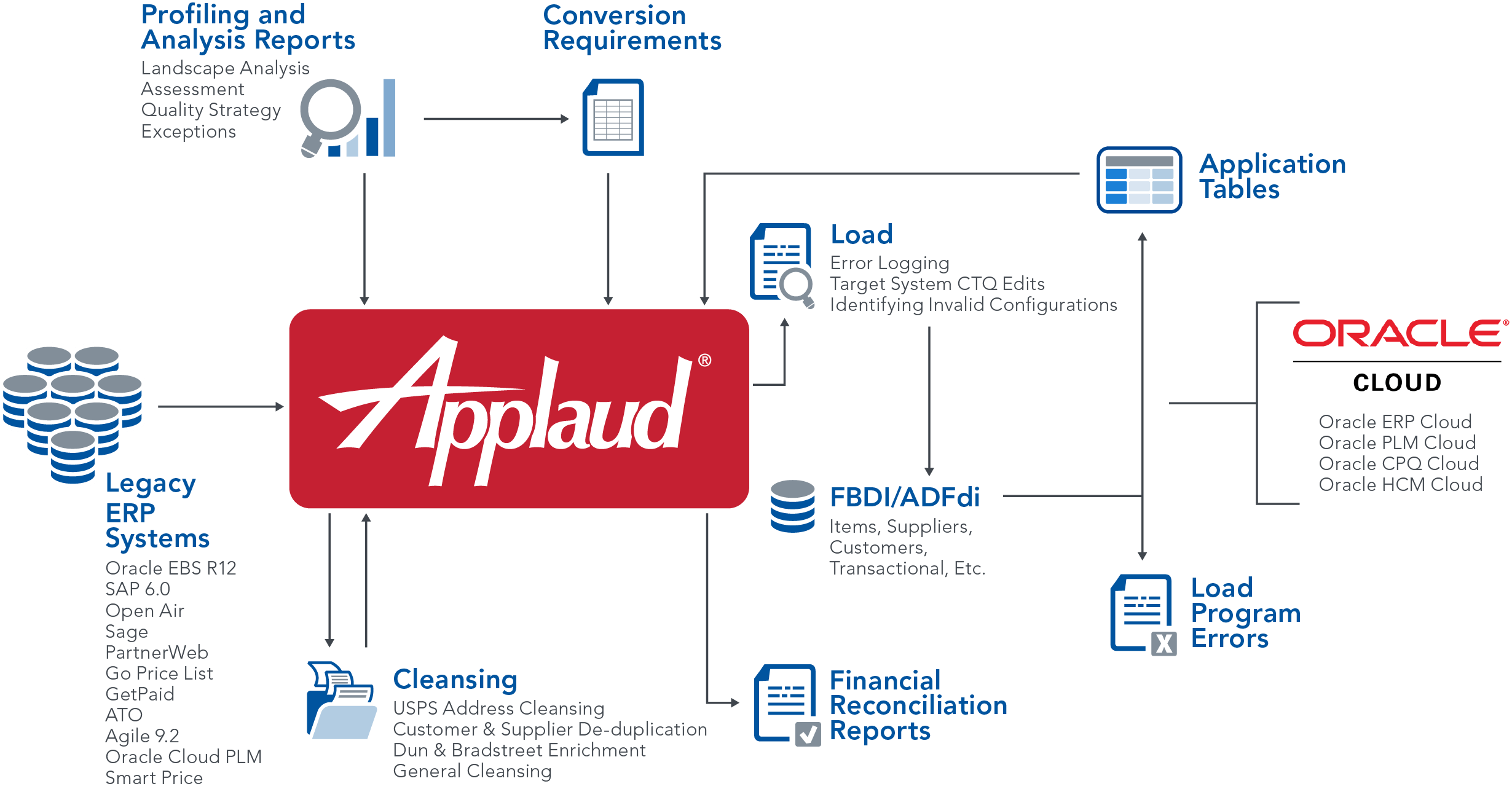
As part of this initiative, the organization decided to move onto Oracle’s Cloud application ecosystem. To successfully carry out this initiative, data from 11 disparate ERP systems needed to be simultaneously migrated into Oracle ERP Cloud, Oracle PLM Cloud, Oracle CPQ Cloud, Oracle HCM Cloud, and Microsoft Dynamics. Recognizing the inherent risks of data migration, as well as the importance and complexity of the data, the organization partnered with Definian to eliminate their data migration risk.
Project Risks
The data migration risk on this implementation was amplified due to internal complexity and external factors.
These factors fit into three main risk areas: Legacy Data Complexity and Quality, Client Resource Stability, and Future State Complexity.
Legacy Data Complexity and Quality
- Significant amounts of duplicated Sales Prospect, Customer, and Supplier data within and across the legacy systems
- Global MDM strategy that called for D&B enrichment to customer and supplier name, which was not accepted by business users
- Legacy customer data models, particularly from SAP, did not clearly fit Oracle’s TCA structure, and needed significant restructuring
Client Resource Stability
- Lack of legacy technical resources
- Lack of client experience with target Oracle ERP Cloud system requirements
- Constant functional, technical, and OSA resource turnover, with inadequate knowledge transfer
- Lack of client data validation effort or understanding
- Global Resourcing, requiring communication across US, EMEA, and APAC regions
Future State Complexity
- Client needed to adapt to the new paradigm of the Cloud from their decades old on premise solutions
- Multiple concurrent projects (Oracle ERP Cloud, PLM Cloud, CPQ Cloud, HCM Cloud, Sales Cloud, and Microsoft Dynamics 365) with inter-dependencies
- Constantly changing business requirements, requiring changes to the conversion programs until days before go live
- Constantly changing configuration in Oracle Cloud, meant not finalizing the Production Pod until days before go live
- Non-existent data load functionality for certain modules and extensive bugs within Oracle ERP Cloud
- Overlapping Project timelines for Wave 1 and Wave 2 due to shifting Client priorities
- Planned and unplanned Oracle Cloud downtime
- Complex Chart of Accounts mapping required detailed reconciliation reports to help the business ensure that the mapping did not unwittingly move money into incorrect Oracle Cloud accounts via AR, AP, and FA conversions
“ I wanted to one more time say thanks for the professionalism, commitment to excellence, and extraordinarily hard work demonstrated by every member of the Definian team. Definian provided an exceptional value … and I personally enjoyed working with your team. Every single person assigned demonstrated the traits mentioned above—and that is rare. ”
– Program Manager
Mitigating Risks
In order to mitigate all the risk factors identified, Definian leveraged risk elimination techniques to ensure that each of the FBDI and ADFdi datasets were ready for cutover. Additionally, Definian ensured that everyone in the project was educated, informed and ready for each aspect of the data migration, even as the Client experienced continual resource turnover.
- Created meaningful reports to help the client better understand their legacy data landscape in order to define requirements and identify legacy data issues.
- Worked with the client to develop a data quality strategy to address legacy data issues, through both legacy data cleanup and translation rules within Definian’s data conversion programs.
- Collaborated with Oracle engineers to troubleshoot Oracle Cloud bugs and help develop brand new load processes where none existed before.
- Definian’s Oracle Cloud CTQ (Critical to Quality) validations predicted conversion results and identified records that fail Oracle Cloud system and client’s functional business requirements, enabling the entire project team to address issues before the actual loads were processed.
- Created and managed the data migration project plan to navigate the implementation team through the project’s critical path and ensure all relevant project team members were aligned.
- Worked with the Global MDM team to define the matching criteria for identifying duplicate customer and supplier data – including combinations and non-exact of name, tax number, D-U-N-S number, and Parent D-U-N-S number.
- Generated an audit trail that tracked all data throughout the migration including the automatically de-duplicated Customers, Suppliers, and Sales Cloud Prospects.
- Delivered and managed readiness dashboards that tracked everything on the conversion cycle from the creation of mapping specifications to final load statistics, which was regularly shared with PMO.
- Created actionable reports to help with data enrichment, including a D&B name override report allowing business users a chance to retain legacy name over D&B enriched name.
Key Activities
In order to deliver on these risk mitigation techniques, the data migration team needed to fully leverage Definian’s EPACTL framework, “One Team, One Tool” approach, and Applaud® data migration software by performing the following activities:
- Extracted the raw data from each of the 11 legacy systems into Applaud’s data repository.
- Automatically profiled each relevant column in each legacy system to assist with the creation of the data conversion requirements.
- Supported the Client in creation of detailed data conversion mapping requirements and specifications
- Deployed integrated analytics/reporting tools to perform deeper analysis on the legacy data set to identify numerous legacy data issues.
- Developed and executed Oracle Cloud specific pre-load validations, identifying missing or invalid configuration prior to each load cycle – allowing the business to address problems prior to each conversion cycle.
- Created custom reconciliation reports for the Accounts Receivable, Accounts Payable, Fixed Assets, and General Ledger modules. Each reconciliation tracked all records from the legacy aging report, though the conversion selection and transformation process, and into Oracle Cloud, ensuring the Client was comfortable and empowered to quickly and easily identify and pinpoint any penny throughout the conversion and loading process.
- Utilized Applaud’s dynamic de-duplication process to merge Suppliers, Customers, and Sales Cloud prospects in the various Oracle Cloud applications.
- Used Applaud’s data transformation capabilities to quickly build stable and repeatable data migration programs which could quickly react to every specification change.
- Provided data migration specialists versed in best practices and techniques to identify prevent, and resolve problems before they became issues.
The Results
The legacy data complexity and quality, client resource stability, and future state complexity increased the risk and made for a challenging project. However, the end result was a resounding success. The team successfully migrated the data from 11 legacy systems into Oracle ERP Cloud, Oracle PLM Cloud, Oracle CPQ Cloud, Oracle HCM Cloud, and Microsoft Dynamics within the specified, 4 day cutover period. Prior to the final production cutover, the team was able to provide the project team with detailed metrics, including the expected load success rate, to support the final “Go/No-Go” decision. With the predicted success rate known ahead of schedule, the team was able to make sure there was a plan in place to address the minimal fallout and PMO was able to confidently make the “Go” decision.
To fully bring the application live, 67 distinct conversion objects were loaded during a 4 day cutover window needed to be loaded. When the final results were tallied, the predicted success rate proved accurate and all reconciliation and data audit criteria passed with flying colors.

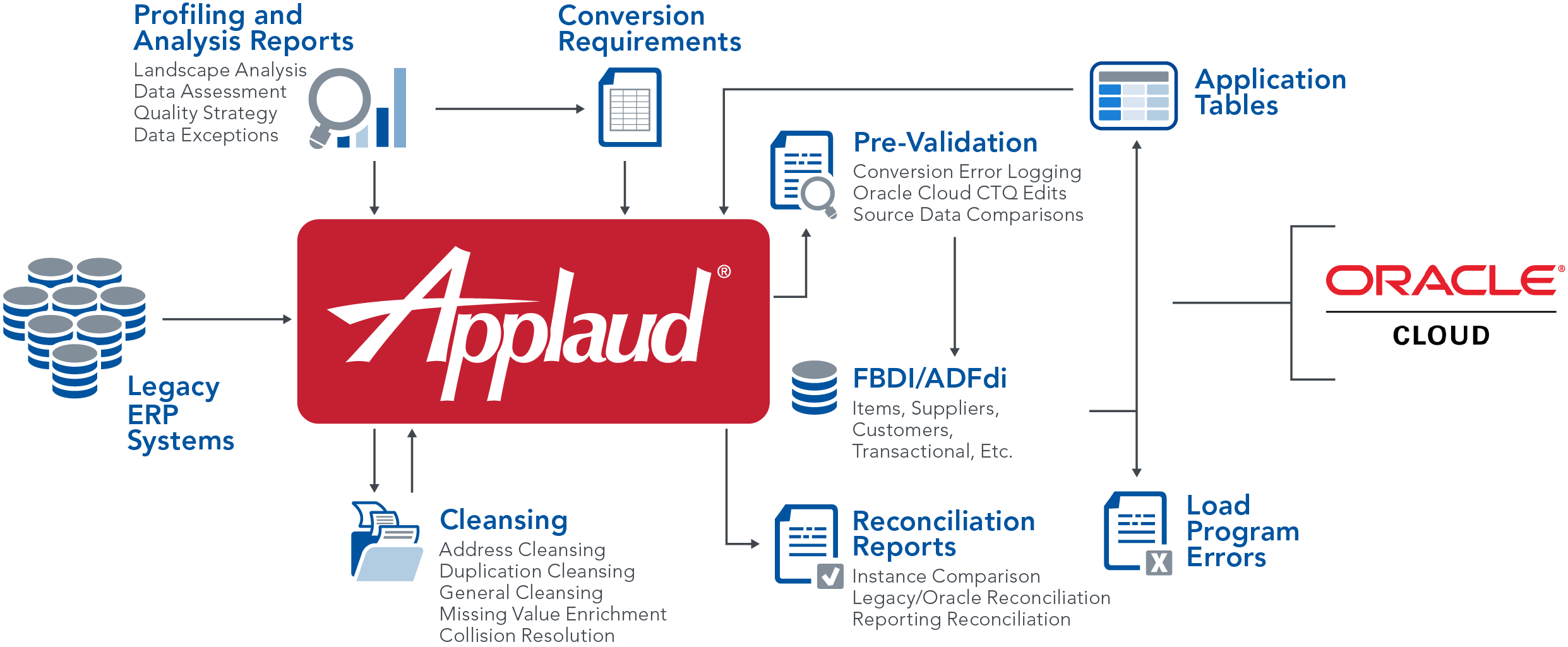
Accelerating Oracle ERP Cloud Implementations Through Data Validation
Validation Challenge
Data validation is critical to the success of every Oracle ERP Cloud implementation. Without knowing how or what to validate, or without the proper tools, validation can lead to unpredictable test cycles, long hours, and project delays. Frequently, a project team’s pre-conversion validation plan heavily relies on the review of FBDI load errors as they occur, resulting in a scramble late in the project to review and repair records. This is followed by a disjointed post-migration validation process that involves spot checking records from the front end, ad hoc Excel dumps, and a manual comparison between legacy and Oracle Cloud reports. In contrast, Definian has developed a way to avoid the headaches traditionally associated with data validation and better ensure data validation success as part of our entire data migration solution.
Over the past 35 years, Definian has focused on data migration and addressing the issues surrounding data validation. We have used our experience to shape our consulting services and optimize our proprietary data migration software. Our process and software is proven across the entire data migration, allowing implementation teams to deliver results on time and within budget. Recently,Definian joined a project team that measured our validation process against their existing process and tools. Their analysis determined that Definian saved them approximately 300 hours on supplier validation alone.
“...Definian has done WONDERS for our data conversion. ... [They] helped us work ahead, shortening the length of the conversion...“
Validation Solution
Definian’s validation and reconciliation approach is designed to accelerate efforts by predicting conversion results before the Oracle ERP Cloud load and by proving results after the migration. This approach is powered by our proprietary data migration software, Applaud®, and is facilitated by our data migration experts.
There are four main aspects to our validation approach:
- Critical-To-Quality (CTQ) validations simulate the data migration and identify conversion issues without executing the Oracle Cloud Load applications. CTQs validate legacy data against both Oracle Cloud configuration and the conversion business requirements. This allows the team to address missing configurations, would-be load errors, and issues within the legacy data, thereby projecting load results prior to execution.
- Conversion Readiness Dashboards provide actionable metrics and insights that give the data cleanup and enrichment greater transparency. Our dashboards serve as platforms for monitoring data quality throughout the implementation, keeping project leadership up to date on the status of cleansing activities.
- Pre-conversion data comparisons bring focus to data differences from conversion cycle to conversion cycle. By isolating delta changes between cycles, the project team can spend their time reviewing the new and unexpected findings rather than repeatedly reviewing the same data.
- Comprehensive post-conversion reconciliation reports accelerate the post-conversion validation and prove the migration by one of three methods. The first and primary method is to extract and juxtapose the converted data from the Oracle Cloud application tables with the original legacy data, allowing users to side-by-side compare current and future states and quickly identify potential issues. The second method compares front end reports from both Oracle Cloud and legacy applications, verifying that business reports balance between current and future states. The third method isolates data differences between the prior and current Oracle Cloud environments, allowing the team to focus on what changed rather than what was already validated.
The Results
We compared our validation approach to other methods commonly employed on data migration projects and Definian’s solution has consistently resulted in greater savings of time and resources, as well as improved data quality.
In addition to the 300 hours we saved on supplier validation, we recently executed our validation method as part of our entire data migration solution during a project that was already in-flight. The adaptation of our solution enabled the client to triple the number of divisions being converted simultaneously, while also cutting in half the allotted time frames between go live dates.
These benefits are made possible by our expert consulting staff, who average over seven years of experience working on data migration projects, and by our Applaud software that we have optimized to make the entire data migration predictable, repeatable, and highly automated.
For over 35 years, some of the most recognizable brands in the world have trusted Definian as their data migration partner. When comparing Definian to their internal teams, our clients consistently tell us that we complete the work “twice as fast with half the resources.”

9 Initial Data Assessment Activities
When a data migration project begins, one of the first steps should be to analyze the legacy data to see what’s there and what’s where. This process is often referred to as the Data Assessment or Landscape Analysis phase of the project. The following 9 activities will help ensure that your implementation gets started on the right foot.
1. Reach out to all business users to identify all legacy data sources.
- Frequently, this process is more difficult than it sounds. In addition to the main systems, people are maintaining separate excel workbooks, access databases, other files, and even notebooks that may or not be officially allowed. While these files might not be allowed, they usually facilitate a feature that is not supported by the current systems, but are critical to run the business. I worked one project for a retailer where legacy system that held all the fixed asset information really old and incredibly difficult to query and develop reports for. The really important day to day work, reporting and queries, and some maintenance took place in an access database.
2. Get access to all of the legacy data sources
- Getting access to legacy data sources is also sometimes harder than it should be. There are security issues and often time many steps of approval need to take place before access is granted. It’s important to start this process right away even if some systems don’t need to be accessed until well into the future.
3. Generate data statistics\Data profile reports on every single relevant table\field across all legacy data sources
- Profiling reports provide some a wealth of information about the data across all of the disparate systems and provide a good reference point for creating the data mapping specifications as well as a starting point for figuring out additional analysis that could be performed.
4. Ask business users about concerns about the data
- Identifying the known pain points, the known gaps, etc. will give an idea as to what types of known data quality issues there are. It will also provide insight into potentially additional data quality checks that should be performed.
5. Capture and define current data governance standards and vision
- Defining the current data governance and data standards is important to know what type of ongoing data checks the organization currently performs. More often than not, there aren’t any data governance standards\processes that are run against the legacy systems. In the cases there are, apply those checks into the analysis reporting and analyze their current procedures for holes. When applying the organization current rules to the data assessment effort, it is frequently discovered that there are many places where the defined standards aren’t in place.
6. Start to talk with target system experts about concerns
- Armed with profile reports and some initial data analysis reports, start to talk with the target system experts and the business around the business requirements for the new system and the concerns that they have. Use these concerns to begin to put together the next level of analysis reports.
7. Generate duplicate candidate and reports
- Duplicate data is almost always an issue and it is a difficult issue to resolve. Duplicate candidate analysis needs to start as soon as possible to get the business thinking about rules for resolving duplicates; whether those rules be automated, manual, a programmatic\manual hybrid.
8. Generate additional in-depth data analysis reports
- With general data statistics in hand, build additional report that build upon the discussions with the legacy and target system experts. At this point, the team should start to have an idea of some of the main data quality issues and start to develop a deeper understanding of what is contained within the legacy systems.
9. Start to develop a data quality strategy
- With the findings that the preliminary analysis and profiling reports uncover, it is possible to start to hash out what the overall data cleansing process will look like for various issues that need to be resolved with the team.
These starting tasks provide a good foundation for a successful data migration project as they allow the data team to quickly provide business a lot of knowledge about the underlying data and allow them to begin develop a strategy on how the data should look in the future.
If you have any questions on data management, data quality, data migration, or just love data, let's connect. My email is steve.novak@definian.com.

A Primer on Data Profiling on Data Migration Projects
What Is Data Profiling?
Data profiling is critical to data migration projects because data quality in legacy systems is usually worse than business users assume. Bad data can interfere with properly functioning businesses.
Imagine invalid contact information preventing customers from receiving invoices or a system showing a quantity on hand of 150 for an item that is completely out of stock and discontinued. By knowing the facts of your data, instead of relying on assumptions and possibly outdated information, steps can be taken to clean up data to more efficiently run your business.
The following are examples of basic types of field level data profiling:
Numeric Field
Amount Paid
- Invalid: 0
- Negative: 0
- Zero: 63,149
- Positive: 404
- Highest: 101,085,153.43
- Lowest: 0
- Total: 495,831,993.65
- Average: 7,801.87
Character Field
Unit of Measure
- Value: Count
- EA: 63104
- EACH: 204
- FT: 19
- GAL: 3
- GRAM: 1
- IN: 1
- LB: 10
Date Field
Creation Date
- Invalid: 0
- Blank: 63,406
- Non-Blank: 147
- Highest: 7/12/2019
- Lowest: 2/5/1991
Pattern
Phone Number
- Value: Count
- (999)999-9999 : 145,035
- 99999 99 99 : 15,013
- A999-999-9999 : 1,529
- +99#99#(99)#9999 : 1,062
- AAAAAAA@AAAAA.AAA : 202
- AAAA : 29
Why Is Data Profiling Important?
Data profiling is critical to data migration projects because data quality in legacy systems is usually worse than business users assume. Bad data can interfere with properly functioning businesses.
Imagine invalid contact information preventing customers from receiving invoices or a system showing a quantity on hand of 150 for an item that is completely out of stock and discontinued. By knowing the facts of your data, instead of relying on assumptions and possibly outdated information, steps can be taken to clean up data to more efficiently run your business.
When Should Data be Profiled?
Data profiling is used during the data assessment, data mapping, data cleansing, and reconciliation phases. Performing data profiling during each of these phases will help with mitigating risk at each step of the way related to major data issues that could result in project delays which ultimately impacts the budget.
During the data assessment, data profiling should be performed on all of the legacy data identified to be converted as part of the migration effort early in the project before a functional team even begins documenting the data mapping specifications. By profiling the data first, the functional and data migration teams can work together to understand the current state of the legacy data and the real data facts can be used to document more accurate and complete data mapping specifications. Data issues are uncovered early in the project rather than in the middle of a test cycle, or worse, during production cut-over, which can inevitably cause delays and increase costs. The earlier these issues are identified, more informed decisions can be made regarding data cleansing efforts and how specific scenarios can be handled during the data transformations.
In the character field profiling example above, there appears to be inconsistent use of values in the UOM field. The data profiling uncovered the values EA vs EACH and IN vs INCH. By knowing this up front, the mapping specifications can be documented accurately to account for all of the values identified without any being inadvertently missed.
Data profiling results can also be used to assist with data cleansing efforts. It’s especially helpful in identifying missing data, such as missing pieces of an address that are required for successful delivery or identify strange patterns in specific fields such as a phone number in an email address field. These types of bad data likely have impacts on the business. Uncovering these types of issues early on allows time for the data to be cleansed in the legacy system and leaving the data in a better state for the target system.
During the post-conversion reconciliation phase, data profiling can be used to validate record counts, translated values, and more.

Data Spelunking: Simple Techniques to Start Understanding Data Landscapes
"You'll never be able to figure out our data", that's what I was told. 48 hours later after putting in some evening hours, mission accomplished. This is not a hypothetical event but rather a recurring theme in what we do at Definian. Every company believes that their data is so unique and different that only they can make sense of it. In some cases, they believe their data is so complex that it can't even be located, let alone pulled out of the underlying database. The truth, however, is that data can only be structured in so many ways. In order for a system to function, that structure must be logical. Whether it's financial data, manufacturing data, or payroll data and whether it resides in a mainframe or relational database, it's all just rows and columns. In order to make sense of it, one needs only to identify the important tables and then understand the relationships between them.
I've personally run into several projects where my client didn't know where the data of interest was stored. They could identify the database and the content they were looking for through the front end, but they couldn't speak to the names of the underlying tables or columns. This always presents a fun challenge and a great opportunity to add value. It’s a process I like to think of as “Data Spelunking” – searching through the database trying to see what you can find and going wherever it takes you.
Assuming the data is in a relational database, there are couple of strategies you can employ to trek through the data and find what you're looking for. Both start with the system catalog at the heart of the database (or data dictionary, information schema, etc.) and are straight forward.
If the database has tables and columns with meaningful names and you're looking for something specific, simply using the catalog to search for tables or tables containing columns with likely names can often quickly lead you to the data you're interested in. For instance, if you were looking at an Oracle database supporting some system and wanted to find tables and columns related to vendors, you could try the following 2 queries (the first for table names by themselves, the second for tables corresponding to column names):
SELECT OWNER, TABLE_NAME FROM ALL_TABLES WHERE TABLE_NAME LIKE '%VENDOR%'
SELECT TABLE_NAME, COLUMN_NAME FROM USER_TAB_COLUMNS A WHERE COLUMN_NAME LIKE '%VENDOR%' ORDER BY TABLE_NAME
Varying the search term and common abbreviations of it may enable you to pinpoint what you're looking for. This works extremely well for something like PeopleSoft where most of the names are very meaningful.
Sometimes, however, that's not enough due to the sheer number of tables in a database, the number of tables sharing the same column names, or the need to identify many types of data. In such a case, the system catalog can be used to generate a list of tables with corresponding row counts for further analysis. You can actually use a SQL Query with the system catalog to construct a whole series of queries that obtain counts for each table. For Oracle (as an example), you could use:
select 'Select ' || '''' || owner || '''' || ' as "Owner_Name", ' || '''' || table_name || '''' || ' as "Table_Name", Count(*) from ' || owner || '.' || table_name || 'union' from all_tables
This query will return a result that is actually series of SQL queries followed by the word "union".
Select 'DEV' as "Owner_Name", 'PS_CUSTOMER' as" Table_Name", Count(*) from DEV.PS_CUSTOMER union
Select 'DEV' as "Owner_Name", 'PS_CUSTOMER_FSS' as" Table_Name", Count(*) from DEV.PS_CUSTOMER_FSS union
Select 'DEV' as "Owner_Name", 'PS_CUSTOMER_LANG' as" Table_Name", Count(*) from DEV.PS_CUSTOMER_LANG union
Select 'DEV' as "Owner_Name", 'PS_CUSTOPT_TEO1' as" Table_Name", Count(*) from DEV.PS_CUSTOPT_TEO1 union
Select 'DEV' as "Owner_Name", 'PS_CUSTOPT_TEO2' as" Table_Name", Count(*) from DEV.PS_CUSTOPT_TEO2 union
Select 'DEV' as "Owner_Name", 'PS_CUSTOPT_TEO3' as" Table_Name", Count(*) from DEV.PS_CUSTOPT_TEO3 union
Select 'DEV' as "Owner_Name", 'PS_CUSTOPT_TEOA' as" Table_Name", Count(*) from DEV.PS_CUSTOPT_TEOA union
Select 'DEV' as "Owner_Name", 'PS_CUST_ADDRESS' as" Table_Name", Count(*) from DEV.PS_CUST_ADDRESS union
Select 'DEV' as "Owner_Name", 'PS_CUST_ADDRSQ_LNG' as "Table_Name", Count(*) from DEV.PS_CUST_ADDRSQ_LNG union
Select 'DEV' as "Owner_Name", 'PS_CUST_ADDR_CNTCT' as "Table_Name", Count(*) from DEV.PS_CUST_ADDR_CNTCT union
Select 'DEV' as "Owner_Name", 'PS_CUST_ADDR_EXS' as "Table_Name", Count(*) from DEV.PS_CUST_ADDR_EXS union
Select 'DEV' as "Owner_Name", 'PS_CUST_ADDR_SEQ' as "Table_Name", Count(*) from DEV.PS_CUST_ADDR_SEQ union
You can then feed this result (minus the final "union") back into a SQL query tool approximately 500 rows at a time and obtain lists of tables along with the current row counts for those tables.
DEV PS_CUSTOMER 21914
DEV PS_CUSTOMER_FSS 14800
DEV PS_CUSTOMER_LANG 568
DEV PS_CUSTOPT_TEO1 0
DEV PS_CUSTOPT_TEO2 0
DEV PS_CUSTOPT_TEO3 0
DEV PS_CUSTOPT_TEOA 0
DEV PS_CUST_ADDRESS 29362
DEV PS_CUST_ADDRSQ_LNG 443
DEV PS_CUST_ADDR_CNTCT 0
DEV PS_CUST_ADDR_EXS 1236
DEV PS_CUST_ADDR_SEQ 27945
These lists can then be added to a spreadsheet, sorted based on row count or name, and quickly scanned to eliminate tables that won't be of interest.
Generally, you will already have an expectation on data volume and can quickly eliminate tables based on counts. For instance, it's unlikely that you're going to migrate data from tables with under 100 rows or maybe even 500. Similarly, there may be some obvious upper bounds on counts for the type of data you're looking for. In most cases you don't have millions of items or customers. High volumes are likely transactional data or temporary tables used for system reporting.
The naming conventions of the tables will also allow you to pare the list down. Suffixes like "TMP" or "RPT" are typically giveaways that these tables are used by system processes and are not the sources of truth you're looking for. Sometimes you'll see date suffixes indicating that someone backed up a table. Scanning through the list, trends should begin to leap off the page. Additionally, you'll be able to pick out situations where multiple tables with similar names have identical row counts allowing you to quickly speculate on relationships you'll want to research further.
Using this process, you can generally reduce the entire database down to a list of likely tables in under an hour. Then start the more tedious process of looking at the content and index structure of each remaining table. I've done it successfully many times over the last decade, and it should work for nearly any relational database with minor tweaks to the queries used.
Happy Spelunking!

Data Governance Playbook: The mission statement for your data
Businesses start with an idea. Buildings start with a blueprint. Your Data Governance plan starts with a playbook. Data Governance is an information management approach that establishes decision rights regarding information. Often designed to mitigate regulatory, compliance, and legal risk exposure for your organization, a data governance program builds in the collaborative tools to help you deliver better products or services, support the Software Development Life Cycle (SDLC), improve your operational effectiveness, and enable more informed decision-making up to the executive level.
Your Data Governance Playbook is the map for your Data Governance plan: the high-level policies and standards that will be the mission statement for managing your information through its lifecycle. Built for business professionals who manage or work with information—data stewards, business analysts, and subject matter experts—as well as IT professionals and compliance officers, the Playbook is your record of why each protocol exists, which standards encapsulate it, and the processes you use to make it happen.
Data Policies, Standards and Processes
Your Data Governance Playbook documents each step in the Data Governance journey:
- Data Governance Policies provide a high-level framework for decisions regarding data;
- Data Governance Standards provide detailed information on how Data Governance Policies should be implemented. Each Data Governance Policy relates to one or more Data Governance Standards;
- Data Governance Processes provide detailed procedures to implement Data Governance Standards. Each Data Governance Standard relates to one or more Data Governance Processes.
Definian Defines Your Data Governance Map
Definianl’s services can expertly guide you through the entire data governance process, from initial recommendations, mentoring, regulatory compliance, and data stewardship training through advanced implementation. We bring a 360-degree view of your information to your Data Governance Playbook design, treating your data not just as a day-to-day tool, but an enterprise asset and the source of your institutional knowledge.

7 Tips for a Successful Phone Interview
So, you’ve made contact with a company, whether online or at a career fair, and you’re moving on to the first stage: the phone interview. Whether this is your first phone interview or you’re practically a professional at this point, here are 7 tips for nailing your interview and securing a spot for yourself in the next round.
1. Come Prepared
Do your research on the company, position you are applying for, and the person interviewing you. Prepare a list of detailed, specific questions for your interviewer and take the time to test out the phone connection in the area in which you will be taking the phone interview.
2. Open with a strong introduction
Most phone interviews are the first step into the interview process. You might have met representatives at a career fair, but the person interviewing you likely has no idea who you are or what you’ve accomplished. Hit them with all your best highlights – where you grew up, your interests, why you chose your major. Relate it back to the job or company for major bonus points!
3. Questions, questions, and more questions
Prepared and thoughtful questions show us a lot – that you prepared for the phone interview, listened to what we told you during the interview, and most importantly, that you did your homework. Interviewers love it when a candidate brings up something discussed during a phone screen or previous interaction because it shows good listening skills and genuine interest.
4. Take a moment, if needed
Stumped? If asked a question and the answer is far, far away in the back corner of your brain, don’t panic. We spent time on our questions and understand if you need a moment to regroup and think of an answer. Plus, it shows you want to provide a thoughtful answer, which is a valuable trait.
5. Be yourself
What are your hobbies? How do you spend your weekends? We are looking for candid responses. This is the perfect time for you to work some personality into the interview and it gives us a better understanding of cultural fit.
6. Answering, is there anything else we should know about you?
Here is your opportunity to give your final elevator pitch, so lay it on us! Reiterate why we should hire you and how you fit in with the company. If done right, you will come across as polished and having the go-getter attitude that companies look to hire.
7. THANK YOU
Send the interviewer a thank you via email or written note. We cannot stress how far this goes – it can even put you a step above a candidate who might be slightly more qualified. The thank you should indicate takeaways from the conversation and appreciation for time spent on the interview.
Remember, an interview is not only a company’s chance to get to know you, but it is also an opportunity for you to get to know them and decide if that company is the right place for you to work. Good luck!

5 Requirements of a Data Migration Repository
The beneficial impact of a central repository and process is enormous. However, in order to realize those benefits, there are important features that the repository must have. Over the years, we have honed and continue to optimize our data repository that our data migration software, Applaud®, uses. If Definian is not part of your implementation, the following features should be part of the repository that is used to facilitate the data migration. If Definian is performing the migration, Applaud makes use of all of these.
1. Quickly replicate the legacy and target table structures
The data repository should be able to automatically create the legacy and target data structures without a DBA or SQL scripts. Throughout a project, data sources are discovered and require immediate access. If it takes more than a minute to set up the meta-data and bring in multiple data sources, project timelines will be impacted.
2. Easily create additional/alter table structures that reside only in the repository
For the repository to serve as an easy to use sandbox, the creation of additional tables and columns that only exist in the repository needs to be simple. Specifications, data enhancement\cleansing spreadsheets, and cross reference information will be constantly changing throughout the course of the project. To react to the constant requests, data structures need to be created, dropped, and altered on the fly.
3. Gracefully handle bad data
Data migration projects are all about handling both bad and good data... but mostly bad. If the migration processes can’t easily handle bad or invalid data, it’s going to be difficult for it to be successful. The repository should gracefully handle character data in numeric fields, invalid dates, etc. without losing rows. If rows are lost upon insert into the repository, the integrity of the data is lost, muddying further data analysis.
4. Beyond simple to get data in and out
Moving data from environment to environment is the core procedure of a data migration. To maximize effectiveness, facilitating the movement of data should be accomplished with minimal effort. When possible, a direct database connection should be used. In some legacy environments, mainframe especially, that’s not always possible.
However, bringing in\exporting out flat, EBCDIC, or any other file format should be a simple process. In the case of mainframe, being able to natively handle EBCDIC, packed numerics, repeating segments, etc is an immeasurable risk reducer, that several of our engagements could not have been successful without those capabilities. Whatever the format, there could be 1000s of tables\files and if it takes more than a small amount of time to get at that data, it could quickly devolve into an unmanageable process. (Read how we successfully handled over 3000 data sources)
5. Fast to build components that analyze the data once it’s in the repository
It is incredibly important that the repository is a place that’s easy to query, combine, harmonize, and separate out data within a single system and across the data landscape. If the repository doesn’t easily facilitate this cross-system analysis, the effectiveness of the repository is diminished.
In addition to a centralized data repository, there are many other techniques and processes involved in the data migration process that further reduce risk on ERP, PLM, and other complex implementations. If you have any questions regarding data migration processes, data issues, and ways to reduce data migration risk, email me at steve.novak@definian.com or call me at 773.549.6945.
Partners & Certifications












